Şu anda kullandığımız bilgisayarların mimarisinin de temelini oluşturan mimaridir. Bu mimarinin sahibi ise John Von Neumann’dır. Neumann 1903-1955 yılları arasında yaşamış Amerikalı matematik ve bilgisayar bilimcisidir. Lisansını kimya üzerine bitirmiştir. Doktorası ise matematik üzerinedir. Ünlü oyunlar teorisi de ona aittir. II. Dünya Savaşı yıllarında Eniac adlı ilk bilgisayarlardan olan hesaplayıcıyı üretmiştir.
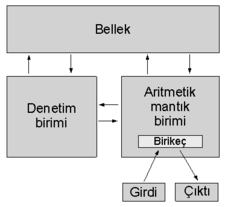
Eniac’ı programlamak için delikli kartlar kullanılıyordu. Bu da normal olarak işlemlerin uzun süre almasına neden oluyordu. Bu olay Neumann’ın saklı programlama yani stored program adlı yapıyı düşünmesini sağladı. Bu yapı da programlama olayı daha esnek olacak ve bilgisayarın içerisinde saklanacaktır. Tabi bu düşünceyi gerçekleştirmek için bazı birimlere ihtiyaç olacaktır. Bu birimler yukarıda saklama işini yapabilecek bellek , işlemleri yapacak olan CPU ve kullanıcıdan bilgi alıp kullanıcıya bilgi veren I/O portlarıdır.
Bu mimarinin eskiye göre en büyük avantajı esnek olmasıdır. Daha önce bir bilgisayarı yapılma amacı dışında kullanmak için yeniden programlamak gerekiyordu. Avantajları olduğu gibi tabii ki bu mimarinin dezavantajları da vardır. En büyük dezavantajı ise hatalardır. Esnek olmayan yapıya göre düzenlenen bir program doğru olarak yazılıp çalıştırıldıktan sonra hiç hata vermeden istediğimiz kadar çalıştırabiliriz. Ama kullanıcıya göre esnek olan ve kullanıcıdan veri alan , o verilere göre sonuç veren programlarda, kullanıcıdan alınan değere hata çıkma ihtimali eskiye oranla yüksektir.
Bu mimaride yapılan işlem Assembly Dersi’nde gördüğümüz yapıdır aslında. Program işaret edilen bellekteki veriyi alır daha sonra ne yapacağına dair kodu alır,işlem gerçekleşir.Bu olay kodlar tamamlanana kadar devam edip gider.Aslında bu yapı bu sebepten dolayı programı yavaşlatır.Bu da en önemli dezavantajlarından biridir.Ama kabul etmeliyiz ki bir yerden fayda görürken elbette ki bunun bir bedeli olacaktır.Bedeli de bu dezavantajlardır. İşlemci ile bellek arası veri taşıma hızının, bellek hızına göre düşük olması işlemcinin büyük bir süre verinin gelmesini beklemesini gerektirir. Günümüzde işlemci ile bellek erişim hızının arasındaki farkın açılmasıyla bu sorun daha da açık olarak fark edilmektedir ve çözüm aramaktadır.
